倒瓶殺菌設備在現代生產中的應用與張家港市鑫淼機械廠的網絡設備整合

倒瓶殺菌設備是一種廣泛應用于食品、飲料和制藥行業的自動化設備,其主要功能是通過將瓶子倒置并噴灑殺菌劑,實現高效、徹底的清潔與殺菌過程。這種設備不僅能有效去除殘留物和微生物,還能提高生產效率,確保產品的衛生安全。在現代工業生產中,倒瓶殺菌設備已成為不可或缺的環節,尤其適用于液體包裝生產線,幫助企業符合嚴格的衛生標準。
張家港市鑫淼機械廠作為一家專業的機械設備制造商,在倒瓶殺菌設備領域擁有豐富的經驗和先進的技術。該廠生產的設備以高穩定性、易操作性和節能環保著稱,能夠根據不同客戶的需求進行定制設計。例如,其設備可能采用不銹鋼材質,配備自動控制系統,確保殺菌過程均勻且無死角。鑫淼機械廠注重售后服務,提供安裝調試和定期維護,幫助用戶延長設備壽命。
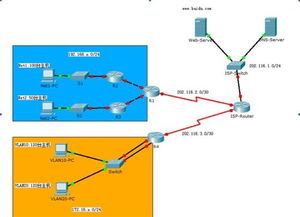
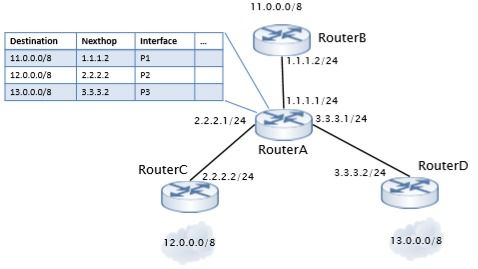
在網絡設備方面,張家港市鑫淼機械廠積極整合現代技術,通過物聯網和遠程監控系統,使倒瓶殺菌設備實現智能化管理。網絡設備的應用包括數據采集、實時監控和故障診斷,這不僅提升了設備運行效率,還降低了人工成本。例如,用戶可以通過手機或電腦遠程查看設備狀態,及時調整參數,預防潛在問題。這種網絡化趨勢體現了鑫淼機械廠在工業4.0背景下的創新精神,幫助客戶構建智能工廠。
倒瓶殺菌設備與網絡設備的結合,代表了現代制造業的升級方向。張家港市鑫淼機械廠憑借其專業制造能力和技術整合,為行業提供了可靠的解決方案。未來,隨著自動化技術的不斷發展,這種設備將在更多領域發揮重要作用,推動產業向高效、智能和可持續的方向邁進。
如若轉載,請注明出處:http://www.0319114.com/product/19.html
更新時間:2026-02-22 11:38:41